
VMFS-6 what changed?
VMFS (Virtual Machine File system) is VMware’s flagship file system used to format the LUNs presented to ESXi hosts, be it locally, via iSCSI or FC storage. VMFS-5 has been ruling over people’s datastores for several years as it was a total game changer compared to VMFS-3, the new reservation mechanism being a big part of it. However, a couple years ago at the end of 2016, VMware GA’d vSphere 6.5 and with it a new version of its file system: VMFS-6, which brought a lot of improvements compared to earlier versions.
Table of Contents
Note that it is still possible to format new datastores with VMFS-5 in vSphere 6.5 if you need it for backward compatibility reasons for example (and this should be the only reason!). Also, know that vSphere 6.7 no longer supports VMFS-3. Prior to upgrading your ESXi host, you should do an upgrade from VMFS-3 to VMFS-5 or they will be upgraded automatically during the host upgrade.
“Upgrading” to VMFS-6
The procedure to move from VMFS-5 to VMFS-6 is probably the reason why some folks have been put off so far from going for it. While it used to be fairly quick and easy to upgrade a datastore in the earlier version, it is no longer possible to upgrade from VMFS-5 to VMFS-6. You will need to destroy your VMFS-5 datastore and reformat it in VMFS-6 so expect a lot of storage vMotions. Though if you are not in a rush of moving to the new version you can keep using VMFS-5 and create any new datastores in VMFS-6 format.
The typical workflow is the following:

- Evacuate a VMFS-5 datastore using storage vMotion (make sure you don’t leave important files on the datastore)
- Delete the empty VMFS-5 datastore
- Create a new VMFS-6 datastore
- Repeat…
Of course be aware that any hosts running vSphere versions earlier than 6.5 will not be able to use the VMFS-6 datastores.
New features of VMFS-6
Support for 4K Native Drives in 512e mode
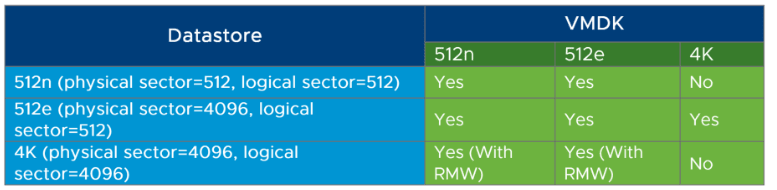
Industry standard disk drives have been using a native 512n byte sector size where the disk exposes physical sectors of 512K in size. However, as drive capacities have skyrocketed over the last few years, this sector size quickly became a bottleneck to improving hard drive capacities and error correction efficiency. This is why the storage industry introduced new advanced formats, which are 512-byte emulation (512e) and 4K Native (4Kn).
512e (the advanced version of 512n) is a format for disks that present physical sectors of 4K and logical ones emulated at 512 Bytes to be used with OSs that do not support 4Kn sectors yet. Its role is mainly to ease the transition towards the 4Kn format which offers the best deal in terms of performance and space efficiency until it becomes widely adopted. This approach enables running legacy operating systems, applications, and existing VMs on servers with 4Kn HDD drives. However, the main drawback of sector emulation is that there is a performance impact compared to 4Kn drives. Check out Dell’s analysis on the subject, it is a very interesting read.
Default SE Sparse
In VMFS-5, the snapshot mechanism for virtual disks smaller than 2TB (most of them) is VMFSSparse while bigger disks benefit from SESparse (more on that below). It is a redo-log that starts empty, immediately after a VM snapshot is taken and expands to the size of its base vmdk. The block size used in VMFSSparse in 512 bytes which limits the storage of snapshot metadata.
SESparse used to be reserved for large disks and View (VDI) workloads. In VMFS-6 it becomes the default format for all snapshots regardless of the disk size. It is similar to VMFSSparse in how it works, however, the big differences lie in the block size of 4K and the space reclamation awareness to save on storage, big deal. Thanks to this mechanism, all blocks that the guest OS deletes are marked. The system sends commands to the SEsparse layer in the hypervisor to unmap those blocks. The unmapping helps to reclaim space allocated by SEsparse once the guest operating system has deleted that data.
A few notes:
- If you migrate a VM with the VMFSsparse snapshot to VMFS-6, the snapshot format changes to SEsparse
- When a VM with a vmdk of the size smaller than 2 TB is migrated to VMFS-5, the snapshot format changes to VMFSsparse
- You cannot mix VMFSsparse redo-logs with SEsparse redo-logs in the same hierarchy
Automatic Space Reclamation
A bit of background to understand this one:
UNMAP is a feature that reclaims blocks that were used but are no longer allocated. For instance, if you delete a VM, the files will be removed from the datastore (think file system, i.e. VMFS), however the storage array itself is not aware of it and still thinks the blocks are allocated. Up until the day when the file system requests a write on the given block and the storage array will say “Oh well, off you go then” and writes the new block instead. Meaning that from a storage array perspective the block was still allocated even though it was available in the file system. Now, this is not necessarily a problem as the file system is what really matters from a VMware perspective (unless you are using thin provisioned storage array luns aggressively but this is another matter), however, it may degrade the relevancy of the storage array metrics regarding space allocation.
This feature used to be available in vSphere 5.0 and was quickly removed in vSphere 5.0 update 1 due to performance issue and disk errors that it was causing. In the later version, VMware exposed a new feature to the vmkfstool command to perform manual UNMAP which implementation wasn’t very efficient.
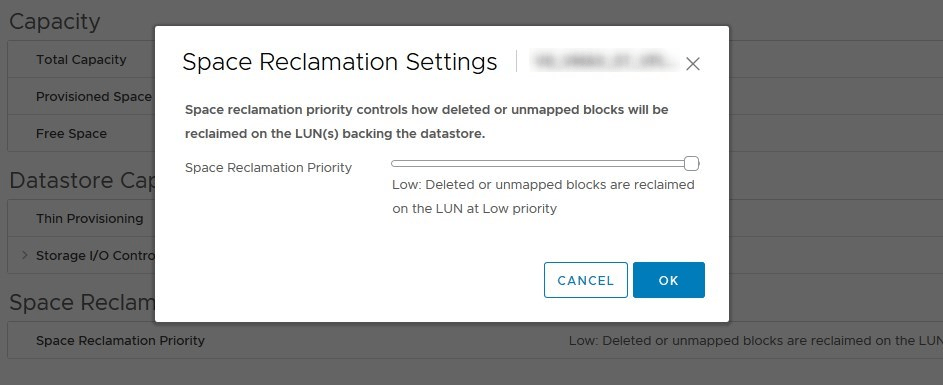
In VMFS-6, VMware figured out a better way to perform UNMAP operations at automatic intervals to reclaim space on the storage. This will please a lot of admins out there! They even exposed the Reclamation Priority setting in the web client that can be tuned on a datastore basis. Now, it may look a bit silly as you can only choose between none and Low which is the default setting so you might wonder “What?”. Well, even though it was greatly improved, a UNMAP operation is still a stressful I/O intensive operation for the storage so VMware wants to stop you from smashing your own arrays to save a few gigs here and there. It can, however, be changed to Medium and High via command line to increase the frequency but it is not recommended to do so unless required by a VMware support engineer.
File block sizes
VMFS-6 introduces two new internal block sizes concept for file creation called LFB (Large File Blocks) set to 512MB and SFB (Small File Blocks) set to 1MB. They are used for files on VMFS-6 datastores. Note that this is not related to the VMFS Block Size which continues to be 1MB.
A file block is chosen according to the disk type:
- Thin disks : Small File Block (SFB)
- Eager Zero Thick (EZT) or Lazy Zeroed Thick (LZT) : Large File Block
At the end of the disk where VMFS cannot use LFB (e.g. remaining 412MB), SFB will be used to complete the last portion.
These new formats have been created to improve file creation performance which is especially true with thick files. Swap files will also benefit from it as they are provisioned thick.
Other improvements
There a lot of other “behind the scenes” improvements in VMFS-6 that are less visible and more in-depth but participate greatly in improving the file system overall.
- System resource files dynamically extended
- New sub-block size back to 64K in size
- Separate system resource file called .jbc.sf for journal blocks tracking
- VM-based Block Allocation Affinity instead of host-based
- Improved device discovery and file system probing
VMFS-5 vs VMFS-6
| Features and Functionalities | VMFS5 | VMFS6 |
|---|---|---|
| Access for ESXi 6.5 hosts | Yes | Yes |
| Access for ESXi hosts version 6.0 and earlier | Yes | No |
| Datastores per host | 512 | 512 |
| 512n storage devices | Yes (default) | Yes |
| 512e storage devices | Yes. Not supported on local 512e devices. | Yes (default) |
| Automatic space reclamation | No | Yes |
| Manual space reclamation through the esxcli command. See Manually Reclaim Accumulated Storage Space | Yes | Yes |
| Space reclamation from guest OS | Limited | Yes |
| GPT storage device partitioning | Yes | Yes |
| MBR storage device partitioning | Yes For a VMFS5 datastore that has been previously upgraded from VMFS3 |
No |
| Storage devices greater than 2 TB for each VMFS extent | Yes | Yes |
| Support for virtual machines with large capacity virtual disks, or disks greater than 2 TB | Yes | Yes |
| Support of small files of 1 KB | Yes | Yes |
| Default use of ATS-only locking mechanisms on storage devices that support ATS. See VMFS Locking Mechanisms. | Yes | Yes |
| Block size | Standard 1 MB | Standard 1 MB |
| Default snapshots | VMFSsparse for virtual disks smaller than 2 TB. SEsparse for virtual disks larger than 2 TB. |
SEsparse |
| Virtual disk emulation type | 512n | 512n |
| vMotion | Yes | Yes |
| Storage vMotion across different datastore types | Yes | Yes |
| High Availability and Fault Tolerance | Yes | Yes |
| DRS and Storage DRS | Yes | Yes |
| RDM | Yes | Yes |
Conclusion
As you can see the storage team over at VMware has not been resting and a lot of improvement have been brought to their flagship file system. As mentioned earlier, going to VMFS-6 does not have to be a priority. You can very well keep rocking VMFS-5 but you should definitely create any new datastore in version 6. Though if your environment is very “static” and you don’t have any new luns in the pipe for the near future, then you should strongly consider going for it anyway to benefit from the new feature and save some space.
Read More:
Difference between VMware VMFS and NFS Datastores
Follow our Twitter and Facebook feeds for new releases, updates, insightful posts and more.

Leave A Comment