Amazon S3 Storage
The BDRSuite supports storing of the backup data on Amazon S3 bucket. Object storage type repository configuration will provide options to choose the Amazon S3 as the backup repository. Amazon S3, an object storage service stores data as objects within the buckets. The object is nothing but the file and any meta data that describes that particular file.
The BDRSuite backs up data in the form of chunks. These chunks will be stored on a temporary cache location which the user has to provide while configuring any object storage repository type.
|

BDRSuite will recognize the repository type using the global repo ID. While the backup job is progressing all the chunks from the cache location will be uploaded to the Amazon S3 storage. Once the upload is complete, the locally stored chunks in the cache will be removed. Ultimately having the back up data stored as objects on the Amazon S3 storage.
|
Setting up Amazon S3 Storage as backup repository
Step 1: In the BDRSuite Backup Server, navigate to Backup Server tab ->Object Storage > Create New Object Storage Repository. You will be taken to the following page where the repository details have to be entered.
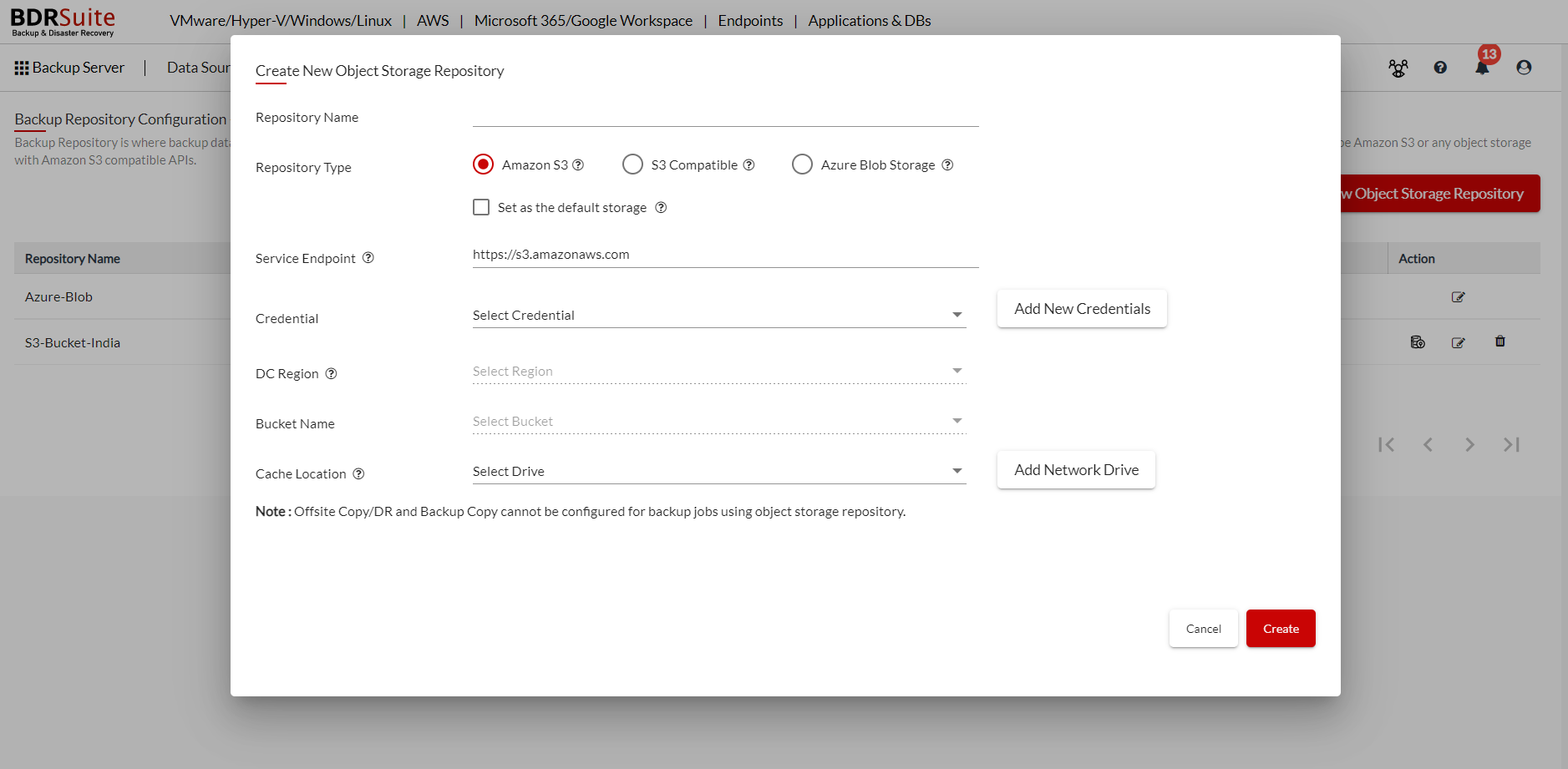
Step 2: Enter the following details;
Repository Name: Give a Name to the repository you are creating
Repository Type: The repository you are creating is the Amazon S3.
Service Endpoint: The Service Endpoint field is auto-filled which establishes a secure connection between the Amazon S3 account and the BDRSuite Backup Server.
Note: By default, HTTPS is used for Service Endpoint connection. If you want to use HTTP instead of HTTPS then make sure that the firewall settings do not interrupt the data transfer during the backup or recovery. |
Note: While using the HTTP, enter the URL in the following format- http://SERVICE_ENDPOINT_URL. |
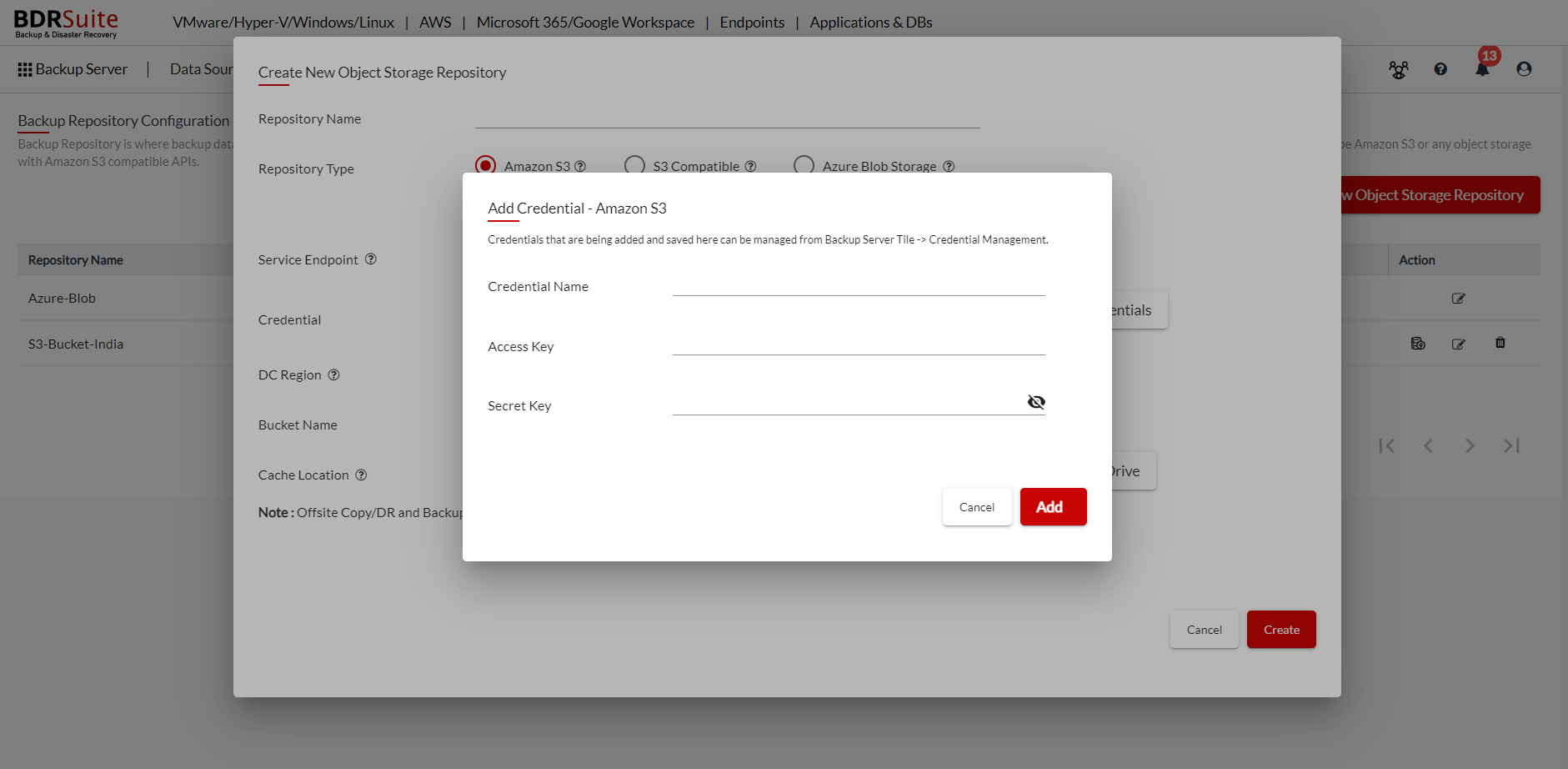
Step 3: From the Credentials drop-down list, select user credentials to access your Amazon S3 account if you already have added the credentials. Otherwise, click Add New Credential button which opens a dialog box.
Specify a credential name to identify your credential record, and provide the Secret Key and Access Key of your Amazon S3 Cloud Storage Account.
You can manage all the S3 Compatible Storage account Credentials from Backup Server Tile -> Credential Management -> AWS S3.
Step 4: Select the DC region
Note: Only the AWS region currently supported in the BDRSuite Backup Server will be listed here. |
Step 5: From the Bucket Name drop-down list, select a container. Make sure that the bucket where you want to store your backup data was created in advance.
Step 6: Choose a cache location to store backup data temporarily before uploading it to Amazon S3 Cloud Storage. Local drives and Network drives added to the BDRSuite Backup Server will be shown in the dropdown list which can be selected as Cache Location.
Note:
|
Step 7: Once all the fields are configured, click the ‘Create’ button upon which the Amazon S3 cloud will be added as Backup Repository.
The created Amazon S3 Cloud Repository can be set as default storage to store the backup data of all jobs configured in the BDRSuite Backup Server (or) you can select the repository for specific jobs during backup configuration.
|